Use Requests modelrequests模組功能: 可以用來讀取網頁原始碼,再藉由正規表達式取得符合資料 import requests url ='https://d86518.weebly.com/python' html = requests.get(url) print(html.text) 用以上這段程式碼就可以抓取我的Python主頁HTML,可再另外加上 html.status_code == 200的條件加以判斷伺服器傳回來的狀態碼沒問題再print,做加一步的檢查 自訂HTTP Headers: Headers 為請求和回應的核心,包含User的瀏覽器、請求頁面、server等資訊,自訂Headers可用程式模擬瀏覽器操作,避過網頁檢查 發送POST請求: 1. 當網頁中有表單要請User key in,大部分需用POST來進行傳送(少數GET) 2. 經常需加入查詢參數,後面會以payload示範 Session / Cookie: 憑證儲存在User端的瀏覽器為Cookie,產生在Server端的為Session (可以以requests.Session()為網站建立Session) 嘗試進入Gossip版吧進入PTT Gossip版抓取網頁資料前,需要按同意的BUTTON,那就製造一個假的通過方式騙騙它  import requests from bs4 import BeautifulSoup payload = { 'from': 'https://www.ptt.cc/bbs/Gossiping/index.html', 'yes': 'yes' #按我同意 button的value設yes } headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36' } rs = requests.Session() rs.post('https://www.ptt.cc/ask/over18', data=payload, headers=headers) #成功進入後再Get頁面 res = rs.get('https://www.ptt.cc/bbs/Gossiping/index.html', headers=headers) soup = BeautifulSoup(res.text, 'html.parser') items = soup.select('.r-ent') for item in items: #單純印text print(item.select('.date')[0].text, item.select('.author')[0].text, item.select('.title')[0].text) BeautifulsoupBeautiful Soup 是一個package,讓開發者撰寫非常少量的程式碼,就可以快速解析網頁 HTML 碼,再應由寫好的功能去抽取想要的HTML Tag,達到網頁解析的目的 使用BS依需求顯示選取內容 html = """ <html><head><title>網頁標題</title></head> <p class="header"><h2>文件標題</h2></p> <div class="content"> <div class="item1"> <a href="http://example.com/one" class="red" id="link1">First</a> <a href="http://example.com/two" class="green" id="link2">Second</a> </div> </div> """ from bs4 import BeautifulSoup sp = BeautifulSoup(html,'html.parser') print("--sp.title--") print(sp.title) print("------------") print("--sp.find('h2')--") print(sp.find('h2')) print("------------") print("--sp.find_all('a')--") print(sp.find_all('a')) print("------------") print("--針對class為red--") print(sp.find_all("a", {"class":"red"})) print("------------") print("--依href做find--") data1=sp.find("a", {"href":"http://example.com/one"}) print(data1.text) # First print("------------") 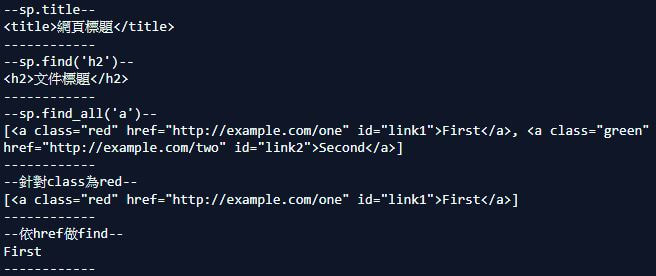
0 評論
發表回覆。 |
